Pandas pivot_table函数
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表(如下图),也体会到它的强大功能,而在pandas中它被称作pivot_table。
DataFrame.pivot_table(values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All',
observed=False
)
pivot_table中的级别将存储在结果DataFrame的索引和列上的MultiIndex对象(分层索引)中。
参数
values :要汇总的列,可选
index : column,Grouper,array或上一个list
如果传递数组,则其长度必须与数据长度相同。
该列表可以包含任何其他类型(列表除外)。
在pivot table索引上进行分组的键。
如果传递了数组,则其使用方式与列值相同。
columns : column,Grouper,array或上一个list
如果传递数组,则其长度必须与数据长度相同。
该列表可以包含任何其他类型(列表除外)。
在pivot table列上进行分组的键。如果传递了数组,
则其使用方式与列值相同。
aggfunc :函数,函数列表,字典,默认
numpy.mean如果传递了函数列表,
则生成的pivot table将具有层次结构列,
其顶层是函数名称(从函数对象本身推论得出)。
如果传递了dict,则键为要汇总的列,
值是函数或函数列表。
fill_value :
scalar(标量),默认为None用于替换缺失值的值。
margins :
bool,默认为False添加所有行/列(例如,小计/总计)。
dropna :
bool,默认为True不要包括所有条目均为NaN的列。
margins_name :
str,默认为"All"当
margins为True时将包含总计的行/列的名称。observed :
bool,默认为False仅当任何 groupers是分类者时才适用。
如果为
True:仅显示分类 groupers 的观测值。如果为
False:显示分类 groupers 的所有值。
返回值
DataFrame Excel样式的pivot table.
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
A B C D E
0 foo one small 1 2
1 foo one large 2 4
2 foo one large 2 5
3 foo two small 3 5
4 foo two small 3 6
5 bar one large 4 6
6 bar one small 5 8
7 bar two small 6 9
8 bar two large 7 9
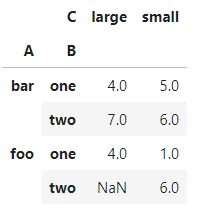
通过计算和来聚合值
table = pd.pivot_table(df, values='D', index=['A', 'B'],
columns=['C'], aggfunc=np.sum)
使用fill_value参数来填充缺失的值
table = pd.pivot_table(df, values='D', index=['A', 'B'],
columns=['C'], aggfunc=np.sum, fill_value=0)

通过跨多个列取平均值来汇总
table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],
aggfunc={'D': np.mean,
'E': np.mean})

可以为任何给定值列计算多种类型的聚合
table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],
aggfunc={'D': np.mean,
'E': [min, max, np.mean]})

案例
pivot_table 有四个最重要的参数index、values、columns、aggfunc,
以火箭队James_Harden本赛季比赛数据作为数据集进行讲解。
读取数据
import pandas as pd
import numpy as np
df = pd.read_csv('James_Harden.csv',encoding='utf8')
df.head()

参数 Index
每个 pivot_table 必须拥有一个index,如果想查看哈登对阵每个队伍的得分,首先我们将对手设置为index
pd.pivot_table(df,index=['对手']).head()

对手成为了第一层索引,还想看看对阵同一对手在不同主客场下的数据,试着将对手与胜负与主客场都设置为index
pd.pivot_table(df,index=[u'对手',u'主客场'])

试着交换下它们的顺序,数据结果一样:
pd.pivot_table(df,index=[u'主客场',u'对手'])
Index就是层次字段,要通过透视表获取什么信息就按照相应的顺序设置字段,所以在进行pivot之前你也需要足够了解你的数据。
参数 Values
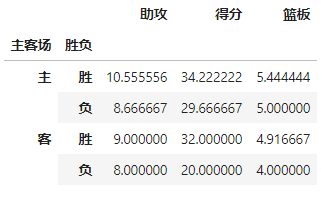
通过上面的操作,我们获取了james harden在对阵对手时的所有数据,而Values可以对需要的计算数据进行筛选,如果我们只需要james harden在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'])
参数 Columns
Columns类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
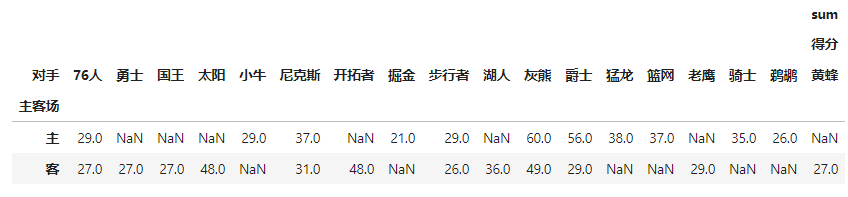
#fill_value填充空值,margins=True进行汇总
pd.pivot_table(df,index=[u'主客场'],columns=[u'对手'],values=[u'得分'],aggfunc=[np.sum])
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.mean],fill_value=0)

query
当表格生成后如何查询某一项数据呢?
ex.根据上表查询哈登对阵灰熊时的数据
table.query('对手 == ["灰熊"]')

Cheat Sheet
